



论文一手脚北卡罗来纳大学教堂山分校张子健丝袜 色情,领导老师为北卡罗来纳大学教堂山分校助理西宾 Huaxiu Yao。共同第一作家为华盛顿大学 Kaiyuan Zheng,其余作家包括来自北卡教堂山的 Mingyu Ding、来自华盛顿大学的 Joel Jang、Yi Li 和Dieter Fox,以及来自芝加哥大学的 Zhaorun Chen、Chaoqi Wang。

论文标题:GRAPE: Generalizing Robot Policy via Preference Alignment
论文连结:https://arxiv.org/abs/2411.19309
神气地址:https://grape-vla.github.io
代码地址:https://github.com/aiming-lab/GRAPE
商榷布景
连年来,视觉-谈话-动作模子(Vision-Language-Action, VLA)在诸多机器东谈主任务上取得了显赫的进展,但它们仍面对一些要害问题,举例由于仅依赖从收效的本质轨迹中进行行径克隆,导致对新任务的泛化才气较差。
此外,这些模子时常通过微调来复制在不同环境下由众人集结的演示数据,这导致了漫衍偏差,并收尾了它们对各类化操作见解(如收尾、安全性和任务完成)的合适才气。
圭臬部分
为了处分这一问题,咱们提议了 GRAPE,一种即插即用的算法,通过偏好对皆晋升机器东谈主政策的泛化才气,并支撑将 VLA 模子对皆到狂放设定的见解。GRAPE 的框架如下图所示:
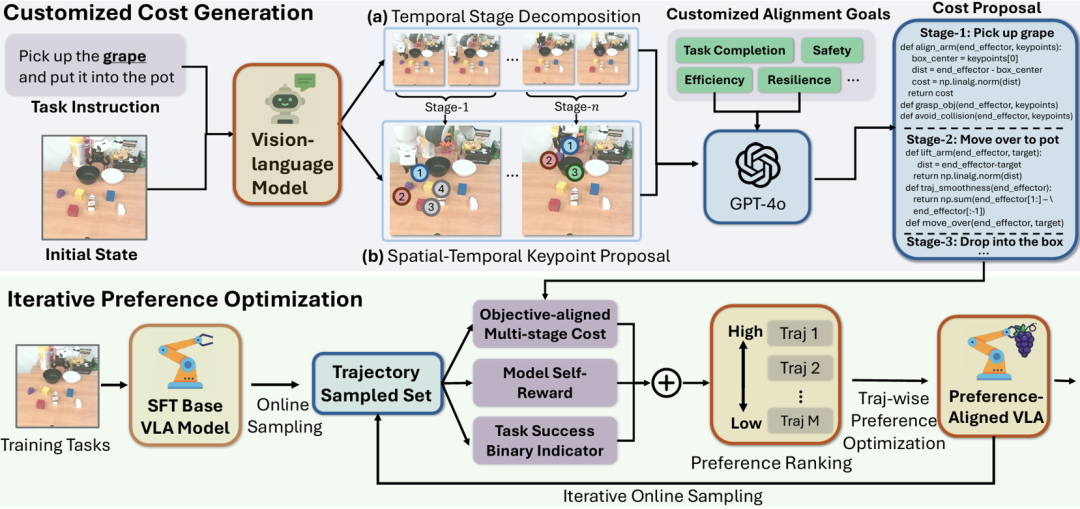
图 1:GRAPE 的框架
GRAPE 带来了以下三大上风,显赫增强了 VLA 模子的泛化性:
GRAPE 在轨迹层面通过强化学习(RL)见解对 VLA 进行对皆丝袜 色情,赋予模子全局决议才气,而不单是是浅陋的行径克隆;
GRAPE 隐式建模了收效和失败尝试中的奖励,从而晋升对各类化任务的泛化才气;
GRAPE 汲取可膨胀的偏好合成算法。GRAPE 通过与狂放见解对皆的偏好对轨迹进行排序,进而使得 VLA 模子能被对皆到设定的见解上。
蛇蝎尤物具体而言,GRAPE 的框架不错被拆成三个部分:Trajectory-wise Preference Optimization、Customized Preference Synthesis 和 Iterative Online Alignment。以下是这三个部分的详备先容:
Trajectory-wise Preference Optimization(轨迹级偏好优化):
GRAPE 将逐步考验的 VLA 模子膨胀到轨迹级别,并通过强化学习(RL)见解进行考验,确保对皆后的政策简略优先遴荐被给与的轨迹,而非被休止的轨迹。
具体而言,咱们基于 DPO 的 Loss 函数进行了改良,引入了一种全新的 TPO_Loss,使得模子简略学习轨迹级别的偏好。咱们诈欺模子在职务中集结的较优与较劣的尝试(永别计为 ζ_w,ζ_l),斥地了 TPO 偏好数据集,最终使得模子在 TPO 考验后在全局层面取得了对皆,并增强了其鲁棒性。
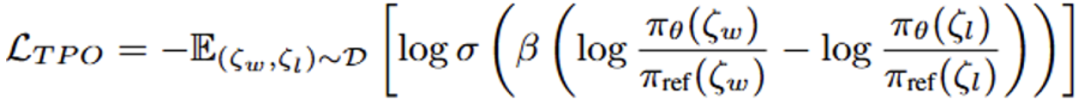
图 2 TPO-Loss 公式
Customized Preference Synthesis(定制化偏好合成):
基于 TPO-Loss 的野心,咱们需要关于轨迹的优劣进行建模,从而构建对应的偏好数据集。关系词,关于一些复杂的机器东谈主任务,并莫得简略用于轨迹排序的奖励模子。
针对这个问题,GRAPE 引入了一种可膨胀算法,将复杂操作任务判辨为寂寞阶段,并通过一个大型视觉-谈话模子提议的要害点,自动指引偏好建模进程中的时空不竭。这些不竭具有纯真性,可证实需求进行定制,使模子与不同见解(如安全性、收尾或任务完成)保握一致。
Iterative Online Alignment(迭代式在线对皆):
GRAPE 通过以下迭代轮回络续优化对皆进程:1)在线样本集结,2)合成偏好排序,3)轨迹级偏好优化。这种圭臬逐步晋升了 VLA 政策的泛化才气,并使其与狂放见解更好地对皆。
实验收尾
真机泛化实验
咱们在域内任务以及五种漫衍外泛化(OOD)任务上评估了 GRAPE 的性能,这些 OOD 任务包括:视觉(新的视觉环境)、主体(未见过的物体)、动作(未见过的操作)、语义(未见过的教唆)寝兵话落地泛化(物体处于未见过的空间位置)。
收尾透露,GRAPE 在这些 OOD 任务上的发扬永别比起始进的 OpenVLA-SFT 模子晋升了 20.7%、27.5%、10.0%、5.0% 和 26.7%。这充分体现了通过偏好对皆进程所已毕的独特泛化才气。
仿真泛化实验
咱们进一步在 Simpler-Env 和 LIBERO 环境中评估了 GRAPE 的性能,要点历练三种 OOD 任务的泛化才气:主体(未见过的物体)、物理属性(未见过的物体尺寸 / 局势)和语义(未见过的教唆)。
收尾透露,GRAPE 在这些 OOD 任务上相较 OpenVLA-SFT 模子永别晋升了 8.0%、12.3% 和 19.0% 的发扬。
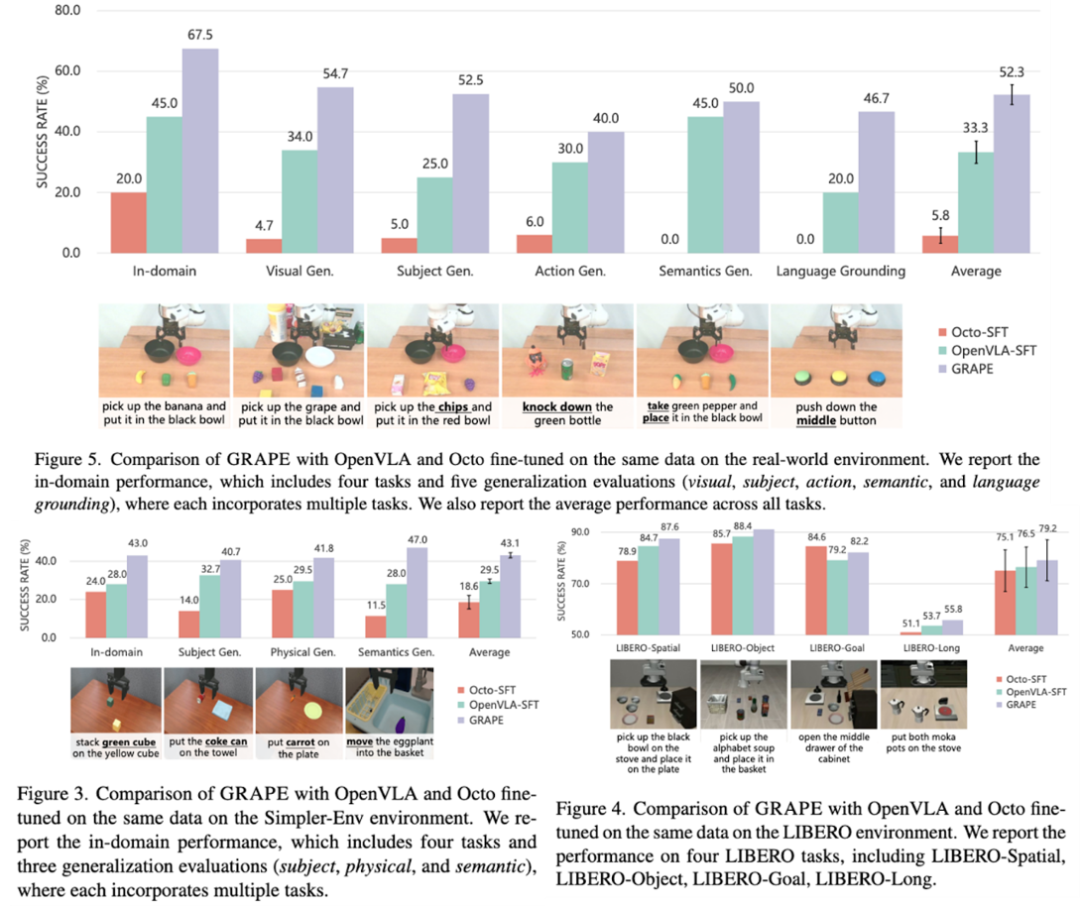
图 3:真机与仿信得过验统计收尾
特定对皆见解分析
GRAPE 简略高效地将机器东谈主政策与通过当然谈话指定的多种见解对皆,举例任务完成、安全性和收尾。这些见解被融入多阶段的资本函数中,进而影响采样轨迹的排序。
实验标明,当对皆见解为更安全或更高效的操作政策时,GRAPE 可将碰撞率批驳 44.31%,或将本质轨迹的长度批驳 11.15%。
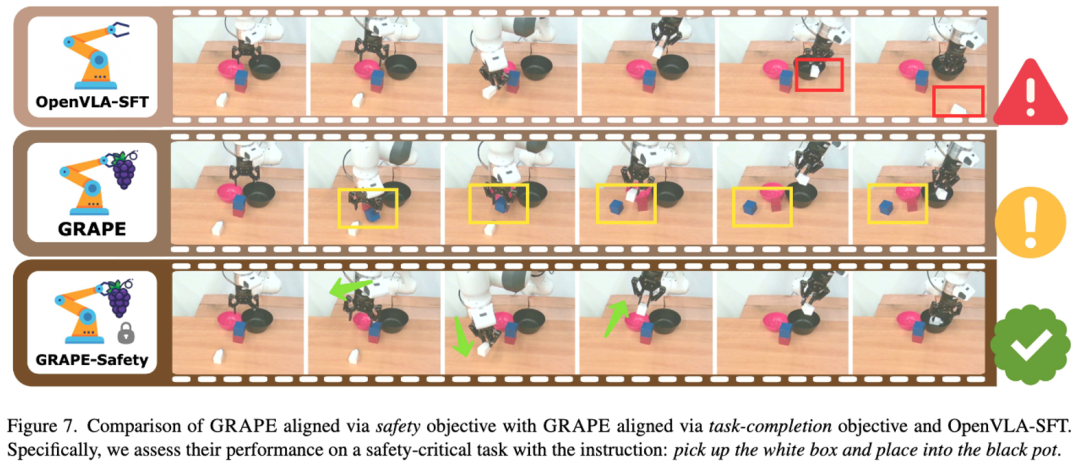
图4:指定的对皆见解(安全),考验后的模子学会了安全地本质操作
论断
本文提议了 GRAPE丝袜 色情,一种即插即用的 VLA 模子对皆框架,在多种机器东谈主任务场景下均能使用,简略基于轨迹偏好晋升机器东谈主政策的泛化才气,并支撑将模子对皆到指定见解。